
首页 > 资讯
点亮未来:TensorRT-LLM 更新加速 AI 推理性能,支持在 RTX 驱动的 Windows PC 上运行新模型
来源: 阅读:(8118)评论:(0) 收藏:(0)
WindowsPC上的AI标志着科技史上的关键时刻,它将彻底改变玩家、创作者、主播、上班族、学生乃至普通PC用户的体验。
微软Ignite全球技术大会发布的新工具和资源包括OpenAIChatAPI的TensorRT-LLM封装接口、RTX驱动的性能改进DirectMLforLlama2、其他热门LLM
WindowsPC上的AI标志着科技史上的关键时刻,它将彻底改变玩家、创作者、主播、上班族、学生乃至普通PC用户的体验。
AI为1亿多台采用RTX GPU的Windows PC和工作站提高生产力带来前所未有的机会。NVIDIA RTX技术使开发者更轻松地创建AI应用,从而改变人们使用计算机的方式。
在微软Ignite大会上发布的全新优化、模型和资源将更快地帮助开发者提供新的终端用户体验。
TensorRT-LLM是一款提升AI推理性能的开源软件,它即将发布的更新将支持更多大语言模型,在RTXGPU8GB及以上显存的PC和笔记本电脑上使要求严苛的AI工作负载更容易完成。
Tensor RT-LLM for Windows即将通过全新封装接口与OpenAI广受欢迎的聊天API兼容。这将使数以百计的开发者项目和应用能在RTXPC的本地运行,而非云端运行,因此用户可以在PC上保留私人和专有数据。
定制的生成式AI需要时间和精力来维护项目。特别是跨多个环境和平台进行协作和部署时,该过程可能会异常复杂和耗时。
AI Workbench 是一个统一、易用的工具包,允许开发者在 PC 或工作站上快速创建、测试和定制预训练生成式 AI 模型和 LLM。它为开发者提供一个单一平台,用于组织他们的AI项目,并根据特定用户需求来调整模型。
这使开发者能够进行无缝协作和部署,快速创建具有成本效益、可扩展的生成式AI模型。加入抢先体验名单,成为首批用户以率先了解不断更新的功能,并接收更新信息。
为支持AI开发者,NVIDIA与微软发布DirectML增强功能以加速最热门的基础AI模型之一的Llama2。除了全新性能标准,开发者现在有更多跨供应商部署可选。
便携式AI
10月,NVIDIA发布TensorRT-LLMfor Windows -- 一个用于加速大语言模型(LLM)推理的库。
本月底发布的TensorRT-LLMv0.6.0 更新将带来至高达5倍的推理性能提升,并支持更多热门的LLM,包括全新Mistral7B和Nemotron-38B。这些LLM版本将可在所有采用8GB及以上显存的GeForceRTX30系列和40系列GPU上运行,从而使最便携的WindowsPC设备也能获得快速、准确的本地运行LLM功能。
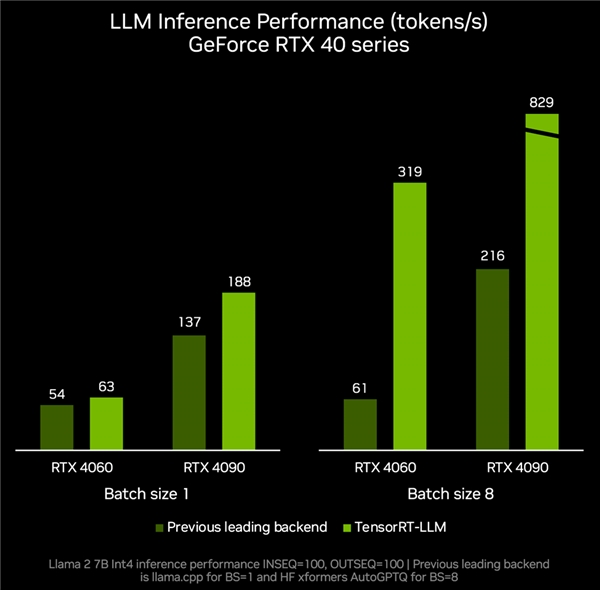
TensorRT-LLM v0.6.0 带来至高达5倍推理性能提升
新发布的TensorRT-LLM可在/NVIDIA/TensorRT-LLM GitHub代码库中下载安装,新调优的模型将在ngc.nvidia.com提供。
从容对话
世界各地的开发者和爱好者将OpenAI的聊天API广泛用于各种应用——从总结网页内容、起草文件和电子邮件,到分析和可视化数据以及创建演示文稿。
这类基于云的AI面临的一大挑战是它们需要用户上传输入数据,因此对于私人或专有数据以及处理大型数据集来说并不实用。
为应对这一挑战,NVIDIA即将启用TensorRT-LLM for Windows,通过全新封装接口提供与OpenAI广受欢迎的ChatAPI类似的API接口,为开发者带来类似的工作流,无论他们设计的模型和应用要在RTXPC的本地运行,还是在云端运行。只需修改一两行代码,数百个AI驱动的开发者项目和应用现在就能从快速的本地AI中受益。用户可将数据保存在PC上,不必担心将数据上传到云端。
使用由 TensorRT-LLM 驱动的 Microsoft VS Code 插件 Continue.dev 编码助手
https://images.nvidia.cn/cn/youtube-replicates/-P17YXulhDc.mp4
此外,最重要的一点是这些项目和应用中有很多都是开源的,开发者可以轻松利用和扩展它们的功能,从而加速生成式AI在RTX驱动的WindowsPC上的应用。
该封装接口可与所有对TensorRT-LLM进行优化的LLM(如,Llama2、Mistral和NVLLM)配合使用,并作为参考项目在GitHub上发布,同时发布的还有用于在RTX上使用LLM的其他开发者资源。
模型加速
开发者现可利用尖端的AI模型,并通过跨供应商API进行部署。NVIDIA和微软一直致力于增强开发者能力,通过DirectMLAPI在RTX上加速Llama。
在10月宣布的为这些模型提供最快推理性能的基础上,这一跨供应商部署的全新选项使将AI引入PC变得前所未有的简单。
开发者和爱好者可下载最新的ONNX运行时并按微软的安装说明进行操作,同时安装最新NVIDIA驱动(将于11月21日发布)以获得最新优化体验。
这些新优化、模型和资源将加速AI功能和应用在全球1亿台RTXPC上的开发和部署,一并加入400多个合作伙伴的行列,他们已经发布了由RTXGPU加速的AI驱动的应用和游戏。
随着模型易用性的提高,以及开发者将更多生成式AI功能带到RTX驱动的WindowsPC上,RTXGPU将成为用户利用这一强大技术的关键。
关于NVIDIA
自1993年成立以来,NVIDIA (NASDAQ: NVDA) 一直是加速计算领域的先驱。NVIDIA 1999年发明的GPU驱动了PC游戏市场的增长,并重新定义了现代计算机图形,开启了现代AI时代,正在推动跨市场的工业数字化。NVIDIA现在是一家全栈计算公司,其数据中心规模的解决方案正在重塑整个行业。更多信息,请访问https://nvidianews.nvidia.com/ 。
# # #
媒体咨询:
Jade Li
NVIDIA GeForce, Studio PR
邮箱:jadli@nvidia.com
版权与免责声明:
凡本网注明“来源:XXX(非本网)”的作品,均转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。如果发现有涉嫌抄袭或侵权的内容,欢迎发送邮件至3210542184@qq.com举报,并提供相关证据,一经查实,本站将立刻删除涉嫌侵权内容。

